检查jdk
java -version
Centos7一般都会带有自己的openjdk,我们一般都回用oracle的jdk,所以要卸载
步骤一:查询系统是否以安装jdk
rpm -qa|grep java
rpm -qa|grep jdk
rpm -qa|grep gcj
步骤二:卸载已安装的jdk
rpm -e --nodeps java-1.8.0-openjdk-1.8.0.131-11.b12.el7.x86_64
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.141-2.6.10.5.el7.x86_64
rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.131-11.b12.el7.x86_64
rpm -e --nodeps java-1.7.0-openjdk-headless-1.8.0.131-11.b12.el7.x86_64
# yum remove java*
步骤三:验证一下是还有jdk
rpm -qa|grep java
java -version
安装JDK8
步骤一:下载linux版本的jdk并上传到linux上 jdk下载地址
Java SE(Java Platform,Standard Edition),应该先说这个,因为这个是标准版本。 Java EE (Java Platform,Enterprise Edition),java 的企业版本 Java ME(Java Platform,Micro Edition),java的微型版本。
步骤二:解压jdk包
[root@localhost ~]# mkdir /data
[root@localhost src]# tar zxf jdk-8u191-linux-x64.tar.gz -C /data/
[root@localhost jdk]# vim /etc/profile
在末尾添加以下内容
export JAVA_HOME=/data/jdk
export JAVA_BIN=/data/jdk/bin
export JAVA_LIB=/data/jdk/lib
export JAVA_JRE=/data/jdk/jre
[root@localhost jdk]# ln -s /data/jdk/bin/java /usr/bin/
[root@localhost jdk]# java -version
步骤三:编辑/etc/profile文件,配置环境变量
export JAVA_HOME=/home/look/dev-software/jdk1.8.0_144
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
或者下载rpm包安装
直接将下载好的jdk-8u151-linux-x64.rpm 安装包 ;上传到自己创建好的JAVA文件下;
cd 命令进入到JAVA文件下使用rpm 命令进行安装
rpm -ivh jdk-8u131-linux-x64.rpm 安装完成后执行
java -version 命令查看安装是否成功
3.1.3 查看安装目录命令,
命令一:which java
命令二:ls -lrt /usr/bin/java
命令三:ls -lrt /etc/alternatives/java
最后将会得出这样的目录 /usr/java/jdk1.8.0_151/jre/bin/java
3.1.4 配置环境变量,执行命令 vi /etc/profile;然后进入编辑模式,在文件的最后添加下面的配置,如图
JAVA_HOME=/usr/javajdk1.8.0_151
JRE_HOME=/usr/java/jdk1.8.0_151/jre
CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
步骤四:生效profile
source /etc/profile
修改默认的JDK位置
vim /etc/sysconfig/elasticsearch
JAVA_HOME=your java path
elasticsearch安装
curl -L -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.1.0-linux-x86_64.tar.gz
tar -xvf elasticsearch-7.1.0-linux-x86_64.tar.gz
cd elasticsearch-7.1.0/bin
./elasticsearch # ./elasticsearch -d 后台运行
# 检查是否启动
GET /
注意:elasticsearch不能用root运行
Exception in thread “main” java.nio.file.AccessDeniedException: /usr/local/elasticsearch-7.1.0/config/jvm.options elasticsearch用户没有该文件夹的权限,执行命令 chown -R es:es /usr/local/elasticsearch/
{“error”:”Content-Type header [application/x-www-form-urlencoded] is not supported”,”status”:406} curl -H “Content-Type: application/json” -XPUT 加上-H参数
修改一个索引
PUT blog/_settings
{
"number_of_replicas": 1
}
#或者
curl -X PUT 'localhost:9200/blog/_settings' -H 'Content-type:Application/json' -d '{"index":{"number_of_replicas":2}}'
#设置自动添加索引
PUT _cluster/settings
{
"persistent": {
"action.auto_create_index": "twitter,index10,-index1*,+ind*" #只允许自动创建索引叫twitter,index10,禁止index1*开头的索引(index10被允许,因为在index*模式前面),以及匹配ind*开头。模式按照给定的顺序进行匹配。
}
}
PUT _cluster/settings
{
"persistent": {
"action.auto_create_index": "false" #完全禁用索引的自动创建。
}
}
PUT _cluster/settings
{
"persistent": {
"action.auto_create_index": "true" #允许使用任何名称自动创建索引。这是默认值。
}
}
记录添加时间戳timestamp
添加时间戳可以在索引数据时指定
$ curl -XPUT localhost:9200/my_index/_doc/1?timestamp=2016-07-14T09:23:38.388Z -d '{
"user" : "kimchy",
"message" : "trying out Elasticsearch"
}'
若使用logstash来做日志收集,logstash会根据事件传输的当前时间自动给事件加上@timestamp字段。
时间戳的数据类型是date,Date类型在Elasticsearch中有三种方式:
传入格式化的字符串,默认是ISO 8601标准
使用毫秒的时间戳,长整型,直接将毫秒值传入即可
使用秒的时间戳,整型
在Elasticsearch内部,对时间类型字段,是统一采用 UTC 时间。在做查询和显示是需要转换时间内容增加8个小时,调整时区为东八区。
使用”||”多种格式
"properties": {
"@timestamp":{
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis",
"type":"date"
}
}
映射mapping
添加映射
PUT twitter
{}
PUT twitter/_mapping
{
"properties": {
"email": {
"type": "keyword"
}
}
}
地理位置
PUT /attractions
{
"mappings": {
"properties": {
"name": {
"type": "string"
},
"mylocaltion": {
"type": "geo_point" //地理坐标
}
}
}
}
修改字段映射
PUT my_index
{
"mappings": {
"properties": {
"name": {
"properties": {
"first": {
"type": "text"
}
}
},
"user_id": {
"type": "keyword"
}
}
}
}
PUT my_index/_mapping
{
"properties": {
"name": {
"properties": {
"last": { //在name对象字段下 添加一个字段last。
"type": "text"
}
}
},
"user_id": {
"type": "keyword",
"ignore_above": 100 //ignore_above从默认值0 更新设置。
}
}
}
dynamic
dynamic有三个值:
true(默认) 新检测到的字段会自动添加到文档,mapping会自动更新
false 新检测到的字段将被忽略。这些字段不会被编入索引,因此无法搜索,但仍会出现在_source返回的匹配字段中。这些字段不会添加到映射中,必须显式添加新字段。
strict 如果检测到新字段,则抛出异常并拒绝该文档。必须将新字段显式添加到映射中。
PUT my_index/_doc/1 //本文档介绍字符串字段username,对象字段 name和name对象下的两个字符串字段,可以称为name.first和name.last。
{
"username": "johnsmith",
"name": {
"first": "John",
"last": "Smith"
}
}
GET my_index/_mapping
PUT my_index/_doc/2
{
"username": "marywhite",
"email": "mary@white.com", //本文档添加了两个字符串字段:email和name.middle。因为默认dynamic为true,所有会自动添加到mapping,可以被索引
"name": {
"first": "Mary",
"middle": "Alice",
"last": "White"
}
}
GET my_index/_mapping
dynamic可以在映射类型级别和每个内部对象上设置该设置 。内部对象从其父对象或映射类型继承该设置。例如
PUT my_index
{
"mappings": {
"dynamic": false, //在类型级别禁用动态映射,因此不会动态添加新的顶级字段。
"properties": {
"user": { //该user对象继承了类型级别设置。
"properties": {
"name": {
"type": "text"
},
"social_networks": {
"dynamic": true, //该user.social_networks对象启用动态映射,因此可以将新字段添加到此内部对象。
"properties": {}
}
}
}
}
}
}
修改数据
在 Elasticsearch 中文档是 不可改变 的,不能修改它们.每当我们执行更新时,Elasticsearch就会删除旧文档,然后索引一个新的文档
POST /customer/_update/1?pretty
{
"doc": { "name": "Jane Doe", "age": 20 }
}
使用script修改数据
[han@node1 ~]$ curl -X POST "localhost:9200/customer/user/1/_update?pretty" -H 'Content-Type: application/json' -d'
{
"script" : "ctx._source.age += 5"
}
'
#返回如下内容
{
"_index" : "customer",
"_type" : "user",
"_id" : "1",
"_version" : 3,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}
'
删除文档
DELETE /customer/_doc/2?pretty
_bulk API批量执行
Bulk API不会因其中一个操作失败而失败。如果单个操作因任何原因失败,它将继续处理其后的其余操作。
批量API返回时,它将为每个操作提供一个状态(按照发送的顺序),以便您可以检查特定操作是否失败
索引两个文档(ID 1 - John Doe 和 ID 2 - Jane Doe)
POST /customer/_bulk?pretty
{"index":{"_id":"1"}}
{"name": "John Doe" }
{"index":{"_id":"2"}}
{"name": "Jane Doe" }
POST /customer/_bulk?pretty
{"update":{"_id":"1"}}
{"doc": { "name": "John Doe becomes Jane Doe" } }
{"delete":{"_id":"2"}} //删除后面不需要跟source
批量插入数据
[han@node1 ~]$ cat accounts.json
{"index":{"_id":"1"}}
{"account_number":1,"balance":39225,"firstname":"Amber","lastname":"Duke","age":32,"gender":"M","address":"880 Holmes Lane","employer":"Pyrami","email":"amberduke@pyrami.com","city":"Brogan","state":"IL"}
{"index":{"_id":"6"}}
{"account_number":6,"balance":5686,"firstname":"Hattie","lastname":"Bond","age":36,"gender":"M","address":"671 Bristol Street","employer":"Netagy","email":"hattiebond@netagy.com","city":"Dante","state":"TN"}
{"index":{"_id":"13"}}
{"account_number":13,"balance":32838,"firstname":"Nanette","lastname":"Bates","age":28,"gender":"F","address":"789 Madison Street","employer":"Quility","email":"nanettebates@quility.com","city":"Nogal","state":"VA"}
{"index":{"_id":"18"}}
{"account_number":18,"balance":4180,"firstname":"Dale","lastname":"Adams","age":33,"gender":"M","address":"467 Hutchinson Court","employer":"Boink","email":"daleadams@boink.com","city":"Orick","state":"MD"}
[han@node1 ~]$ curl -H "Content-Type: application/json" -XPOST "localhost:9200/bank/_doc/_bulk?pretty&refresh" --data-binary "@accounts.json"
The Search API
运行搜索有两种基本方法:一种是把检索参数放在URL后面,另一种是放在请求体里面。相当于HTTP的GET和POST请求
# 方法1
curl -X GET "localhost:9200/bank/_search?q=*&sort=account_number:asc&pretty"
# 方法2
curl -X GET "localhost:9200/bank/_search" -H 'Content-Type: application/json' -d'
{
"query": { "match_all": {} },
"sort": [
{ "account_number": "asc" }
]
}
'
查询语言
Elasticsearch提供了一种JSON风格的语言,您可以使用这种语言执行查询。这被成为查询DSL。
注意:如果size没有指定,则默认是10
下面的例子执行match_all,并返回第10到19条文档:
curl -X GET "localhost:9200/bank/_search" -H 'Content-Type: application/json' -d'
{
"query": { "match_all": {} },
"from": 10,
"size": 10
}
'
from参数(从0开始)指定从哪个文档索引开始,并且size参数指定从from开始返回多少条。这个特性在分页查询时非常有用。
注意:如果没有指定from,则默认从0开始
下面的例子返回account_number为20的文档,相当于SELECT * FROM bank WHERE account_number = 20
curl -X GET "localhost:9200/bank/_search" -H 'Content-Type: application/json' -d'
{
"query": { "match": { "account_number": 20 } }
}
'
下面的例子返回address中包含”mill”的账户,相当于SELECT * FROM bank WHERE address LIKE ‘%mill%’:
curl -X GET "localhost:9200/bank/_search" -H 'Content-Type: application/json' -d'
{
"query": { "match": { "address": "mill" } }
}
'
下面的例子返回address中包含”mill”或者”lane”的账户:
curl -X GET "localhost:9200/bank/_search" -H 'Content-Type: application/json' -d'
{
"query": { "match": { "address": "mill lane" } }
}
'
区别”match”:返回包含”mill lane”短语的账户:
GET / bank / _search
{
"query":{"match_phrase":{"address":"mill lane"}}
}
_source返回指定字段
GET bank/_search
{
"query": {
"match": {
"state": "OK"
}
},
"sort":
{
"age": {
"order": "desc"
}
},
"_source": ["account_number","balance"]
}
bool查询允许我们使用布尔逻辑将较小的查询组合成较大的查询 下面的例子将两个match查询组合在一起,返回address中包含”mill”和”lane”的账户,相当于SELECT * FROM bank WHERE address LIKE ‘%mill%lane%’:
curl -X GET "localhost:9200/bank/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"bool": {
"must": [
{ "match": { "address": "mill" } },
{ "match": { "address": "lane" } }
]
}
}
}
'
上面是bool must查询,下面这个是bool shoud查询,must相当于and,shoud相当于or,must_not相当于!:
curl -X GET "localhost:9200/bank/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"bool": {
"should": [
{ "match": { "address": "mill" } },
{ "match": { "address": "lane" } }
]
}
}
}
'
我们可以在bool查询中同时组合must、should和must_not子句。此外,我们可以在任何bool子句中编写bool查询,以模拟任何复杂的多级布尔逻辑。
下面的例子是一个综合应用: 相当于SELECT * FROM bank WHERE age LIKE ‘%40%’ AND state NOT LIKE ‘%ID%’
curl -X GET "localhost:9200/bank/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"bool": {
"must": [
{ "match": { "age": "40" } }
],
"must_not": [
{ "match": { "state": "ID" } }
]
}
}
}
'
布尔过滤器编辑
一个 bool 过滤器由三部分组成:
{
"bool" : {
"must" : [],
"should" : [],
"must_not" : [],
}
}
must
所有的语句都 必须(must) 匹配,与 AND 等价。
must_not
所有的语句都 不能(must not) 匹配,与 NOT 等价。
should
至少有一个语句要匹配,与 OR 等价。
分数是一个数值,它是文档与我们指定的搜索查询匹配程度的相对度量(PS:相似度)。分数越高,文档越相关,分数越低,文档越不相关。
但是查询并不总是需要产生分数,特别是当它们仅用于“过滤”文档集时。Elasticsearch检测到这些情况并自动优化查询执行,以便不计算无用的分数。
我们在前一节中介绍的bool查询还支持filter子句,该子句允许使用查询来限制将由其他子句匹配的文档,而不改变计算分数的方式。
作为一个例子,让我们引入range查询,它允许我们通过一系列值筛选文档。这通常用于数字或日期过滤。
下面这个例子用一个布尔查询返回所有余额大于等于20000并且小于等等30000的账户。
curl -X GET "localhost:9200/bank/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"bool": {
"must": { "match_all": {} },
"filter": {
"range": {
"balance": {
"gte": 20000,
"lte": 30000
}
}
}
}
}
}
'
在查询的字段只有一个值的时候,应该使用term而不是terms,在查询字段包含多个的时候才使用terms(类似于sql中的in、or),使用terms语法,JSON中必须包含数组。
{
"terms": {
"lang": [1]
}
},
GET /forum/article/_search
{
"query": {
"constant_score": {
"filter": {
"terms": {
"articleID.keyword": ["吃饭","游戏"]
}
}
}
}
}
term,match,match_phase的区别
term:代表完全匹配,即不进行分词器分析,文档中必须包含整个搜索的词汇。而match,match_phase会被先分词然后再查询
{
"query":{
"term":{
"foo": "Hello world"
}
}
}
那么只有在字段中存储了“Hello world”的数据才会被返回
match模糊匹配,先对输入进行分词,对分词后的结果进行查询,文档只要包含match查询条件的一部分就会被返回
match_phase习语匹配,查询确切的phase,在对查询字段定义了分词器的情况下,会使用分词器对输入进行分词,然后返回满足下述两个条件的document:
1.match_phase中的所有term都出现在待查询字段之中
2.待查询字段之中的所有term都必须和match_phase具有相同的顺序
text和keyword的区别
- text类型:会分词,先把对象进行分词处理,然后再再存入到es中。
当使用多个单词进行查询的时候,当然查不到已经分词过的内容! - keyword:不分词,没有把es中的对象进行分词处理,而是存入了整个对象 ,ignore_above这个字段默认忽略所有长度超过 256个字符串
对超过 ignore_above 的字符串,analyzer 不会进行处理;所以就不会索引起来。
分组聚集
按照state分组
curl -X GET "localhost:9200/bank/_search" -H 'Content-Type: application/json' -d'
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword"
}
}
}
}
'
term查询只是不采用分词器和分析器,也就是说如果字段值:Quick brown foxes leap over lazy dogs in summer,若使用term查询字符串:dogs,还是可以查出来,但是查询字符串:Dogs或者Dogs summer就查不出来了,因为没有使用分词和分析
按照state分组,然后取balance的平均值
curl -X GET "localhost:9200/bank/_search" -H 'Content-Type: application/json' -d'
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword"
},
"aggs": {
"average_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}
'
按照年龄分组,并计算平均balance,结果按照balance平均倒序输出
GET bank/_search
{
"size": 0,
"query": {"match_all": {} },
"aggs": {
"group_by_age": {
"terms": {
"field": "age",
"size": 10,
"order": {
"avg_of_balance": "desc"
}
},
"aggs": {
"avg_of_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}
下面这个例子展示了我们如何根据年龄段(20-29岁,30-39岁,40-49岁)来分组,然后根据性别分组,最后得到平均账户余额,每个年龄等级,每个性别:
GET /bank/_search
{
"size": 0,
"aggs": {
"group_by_age": {
"range": {
"field": "age",
"ranges": [
{
"from": 20,
"to": 30
},
{
"from": 30,
"to": 40
},
{
"from": 40,
"to": 50
}
]
},
"aggs": {
"group_by_gender": {
"terms": {
"field": "gender.keyword"
},
"aggs": {
"average_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}
}
}
group_by_make 聚合,它是一个 terms 桶(嵌套在 colors 、 terms 桶内)。这意味着它 会为数据集中的每个唯一组合生成( color 、 make )(汽车颜色,制造商案例)元组。
curl -X GET "localhost:9200/cars/transactions/_search" -H 'Content-Type: application/json' -d'
{
"size" : 0,
"aggs": {
"colors": {
"terms": {
"field": "color"
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
},
"group_by_make": {
"terms": {
"field": "make"
}
}
}
}
}
}
'
可以定义多个字段为group,一下例子中的by_size,和by_material表示以size和material分组
{
"query": {
"match": {
"title": "Beach"
}
},
"aggs": {
"by_size": {
"terms": {
"field": "size"
}
},
"by_material": {
"terms": {
"field": "material"
}
}
}
}
missing处理没有值的文档,如下会把grade没有值的文档归为grade=10的分组
POST /exams/_search?size=0
{
"aggs" : {
"grade_avg" : {
"avg" : {
"field" : "grade",
"missing": 10
}
}
}
}
range 查询同样可以应用在日期字段上:
GET dss_checkin_index/_search
{
"size": 0,
"query": {
"bool": {
"must": [
{
"range": {
"checkInTime": {
"gte": "2015-06-01 00:00:00 000",
"lt": "2015-07-01 00:00:00 000"
}
}
}
]
}
},
"aggs": {
"name": {
"terms": {
"field": "user.keyword"
},
"aggs": {
"top_users": {
"top_hits": {
"size": 100
}
}
}
}
}
}
top_hits的作用就是在每个组下面的数据进行筛选
size:每组显示的数据
sort:每组的排序
_source.includes:每组显示哪些属性值
案例如下:
PUT /my_index/_bulk?refresh
{"index":{"_id":1}}
{"name":"小明","content":"深圳大厦很高的","age":12}
{"index":{"_id":2}}
{"name":"小明","content":"深圳天气还是不错的","age":14}
{"index":{"_id":3}}
{"name":"小红","content":"深圳交通很棒","age":13}
{"index":{"_id":4}}
{"name":"小明","content":"深圳是很好是吧","age":16}
{"index":{"_id":5}}
{"name":"小春","content":"美女在深圳很多","age":16}
{"index":{"_id":6}}
{"name":"小红","content":"深圳的帅哥很多","age":16}
GET /my_index/_search
{
"size": 0,
"aggs": {
"group_agg":{
"terms": {
"field": "name.keyword"
},
"aggs": {
"top_data": {
"top_hits": {
"size": 2,
"sort": [
{
"age": {
"order": "desc"
}
}
],
"_source": {
"includes": ["content","age"]
}
}
}
}
}
}
}
range 查询支持对 日期计算(date math) 进行操作,比方说,如果我们想查找时间戳在过去一小时内的所有文档:
"range" : {
"timestamp" : {
"gt" : "now-1h"
}
}
在某个日期后加上一个双管符号 (||) 并紧跟一个日期数学表达式,如: 早于 2014 年 1 月 1 日加 1 月(2014 年 2 月 1 日 零时)
"range" : {
"timestamp" : {
"gt" : "2014-01-01 00:00:00",
"lt" : "2014-01-01 00:00:00||+1M"
}
}
字符串范围编辑
range 查询同样可以处理字符串字段, 字符串范围可采用 字典顺序(lexicographically) 或字母顺序(alphabetically)。
例如,下面这些字符串是采用字典序(lexicographically)排序的:
5, 50, 6, B, C, a, ab, abb, abc, b
查找从 a 到 b (不包含)的字符串
"range" : {
"title" : {
"gte" : "a",
"lt" : "b"
}
}
处理 Null 值,exists,missing
null, [] (空数组)和 [null] 所有这些都是等价的,它们无法存于倒排索引中 例文档并用标签的例子来说明,以下文档每个tags都对应不同的值:
POST /my_index/posts/_bulk
{ "index": { "_id": "1" }}
{ "tags" : ["search"] }
{ "index": { "_id": "2" }}
{ "tags" : ["search", "open_source"] }
{ "index": { "_id": "3" }}
{ "other_field" : "some data" }
{ "index": { "_id": "4" }}
{ "tags" : null }
{ "index": { "_id": "5" }}
{ "tags" : ["search", null] }
以上文档集合中 tags 字段对应的倒排索引如下:
Token DocIDs
open_source 2
search 1,2,5
找到那些被设置过标签字段的文档,并不关心标签的具体内容。只要它存在于文档中即可,
GET /my_index/posts/_search
{
"query" : {
"constant_score" : {
"filter" : {
"exists" : { "field" : "tags" }
}
}
}
}
这个查询返回 3 个文档:
"hits" : [
{
"_id" : "1",
"_score" : 1.0,
"_source" : { "tags" : ["search"] }
},
{
"_id" : "5",
"_score" : 1.0,
"_source" : { "tags" : ["search", null] }
},
{
"_id" : "2",
"_score" : 1.0,
"_source" : { "tags" : ["search", "open source"] }
}
]
尽管文档 5 有 null 值,但它仍会被命中返回。字段之所以存在,是因为标签有实际值( search )可以被索引,所以 null 对过滤不会产生任何影响。
missing 查询本质上与 exists 恰好相反: 它返回某个特定 无 值字段的文档 我们将前面例子中 exists 查询换成 missing 查询:
GET /my_index/posts/_search
{
"query" : {
"constant_score" : {
"filter": {
"missing" : { "field" : "tags" }
}
}
}
}
按照期望的那样,我们得到 3 和 4 两个文档(这两个文档的 tags 字段没有实际值):
"hits" : [
{
"_id" : "3",
"_score" : 1.0,
"_source" : { "other_field" : "some data" }
},
{
"_id" : "4",
"_score" : 1.0,
"_source" : { "tags" : null }
}
]
索引别名和零停机
PUT /my_index_v1
PUT /my_index_v1/_alias/my_index # 设置别名 my_index 指向 my_index_v1
GET /*/_alias/my_index # 检测这个别名指向哪一个索引:
GET /my_index_v1/_alias/* # 哪些别名指向这个索引:
#将数据从 my_index_v1 索引到 my_index_v2,一旦我们确定文档已经被正确地重索引了,我们就将别名指向新的索引
#一个别名可以指向多个索引,所以我们在添加别名到新索引的同时必须从旧的索引中删除它。这个操作需要原子化,这意味着我们需要使用 _aliases 操作:
POST /_aliases
{
"actions": [
{ "remove": { "index": "my_index_v1", "alias": "my_index" }},
{ "add": { "index": "my_index_v2", "alias": "my_index" }}
]
}
refresh 和flush区别
elasticsearch中有两个比较重要的操作:refresh 和 flush
refresh操作
当我们向ES发送请求的时候,我们发现es貌似可以在我们发请求的同时进行搜索。而这个实时建索引并可以被搜索的过程实际上是一次es 索引提交(commit)的过程,如果这个提交的过程直接将数据写入磁盘(fsync)必然会影响性能,所以es中设计了一种机制,即:先将index-buffer中文档(document)解析完成的segment写到filesystem cache之中,这样避免了比较损耗性能io操作,又可以使document可以被搜索。以上从index-buffer中取数据到filesystem cache中的过程叫做refresh。
refresh操作可以通过API设置:
POST /index/_settings
{“refresh_interval”: “10s”}
当我们进行大规模的创建索引操作的时候,最好将将refresh关闭。
POST /index/_settings
{“refresh_interval”: “-1″}
es默认的refresh间隔时间是1s,这也是为什么ES可以进行近乎实时的搜索。
flush操作与translog
我们可能已经意识到如果数据在filesystem cache之中是很有可能在意外的故障中丢失。这个时候就需要一种机制,可以将对es的操作记录下来,来确保当出现故障的时候,保留在filesystem的数据不会丢失,并在重启的时候可以从这个记录中将数据恢复过来。elasticsearch提供了translog来记录这些操作。
当向elasticsearch发送创建document索引请求的时候,document数据会先进入到index buffer之后,与此同时会将操作记录在translog之中,当发生refresh时(数据从index buffer中进入filesystem cache的过程)translog中的操作记录并不会被清除,而是当数据从filesystem cache中被写入磁盘之后才会将translog中清空。而从filesystem cache写入磁盘的过程就是flush。可能有点晕,我画了一个图帮大家理解这个过程:
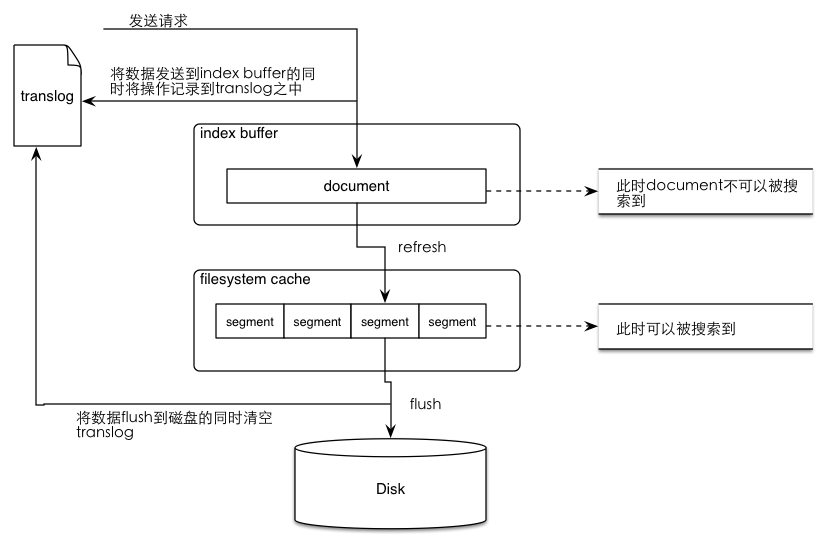
总结一下translog的功能:
1.保证在filesystem cache中的数据不会因为elasticsearch重启或是发生意外故障的时候丢失。
2.当系统重启时会从translog中恢复之前记录的操作。
3.当对elasticsearch进行CRUD操作的时候,会先到translog之中进行查找,因为tranlog之中保存的是最新的数据。
4.translog的清除时间时进行flush操作之后(将数据从filesystem cache刷入disk之中)。
再总结一下flush操作的时间点:
1.es的各个shard会每个30分钟进行一次flush操作。
2.当translog的数据达到某个上限的时候会进行一次flush操作。
有关于translog和flush的一些配置项:
index.translog.flush_threshold_ops:当发生多少次操作时进行一次flush。默认是 unlimited。
index.translog.flush_threshold_size:当translog的大小达到此值时会进行一次flush操作。默认是512mb。
index.translog.flush_threshold_period:在指定的时间间隔内如果没有进行flush操作,会进行一次强制flush操作。默认是30m。
index.translog.interval:多少时间间隔内会检查一次translog,来进行一次flush操作。es会随机的在这个值到这个值的2倍大小之间进行一次操作,默认是5s。
elasticsearch常用插件
CentOS 7.X 下安装ElasticSearch-Head插件
cerebro下载地址