Elasticsearch 文档索引过程描述 协调节点默认使用文档ID参与计算(也支持通过routing),以便为路由提供合适的分片。 shard = hash(document_id) % (num_of_primary_shards)
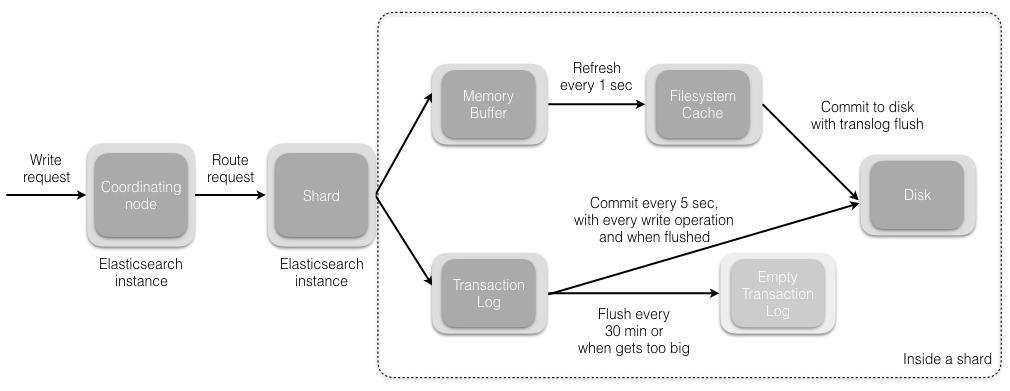
1.当分片所在的节点接收到来自协调节点的请求后,会将请求写入到Memory Buffer,然后定时(默认是每隔1秒)写入到Filesystem Cache,这个从Momery Buffer到Filesystem Cache的过程就叫做refresh;
2.当然在某些情况下,存在Momery Buffer和Filesystem Cache的数据可能会丢失,ES是通过translog的机制来保证数据的可靠性的。其实现机制是接收到请求后,同时也会写入到translog中,当Filesystem cache中的数据写入到磁盘中时,才会清除掉,这个过程叫做flush。
3.在flush过程中,内存中的缓冲将被清除,内容被写入一个新段,段的fsync将创建一个新的提交点,并将内容刷新到磁盘,旧的translog将被删除并开始一个新的translog。
4.flush触发的时机是定时触发(默认30分钟)或者translog变得太大(默认为512M)时。
Elasticsearch搜索的过程描述
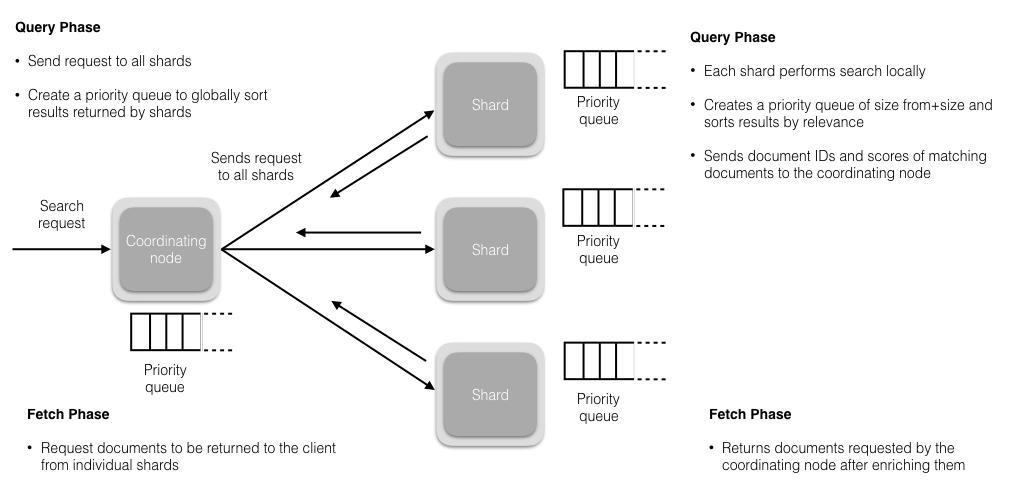
1.搜索被执行成一个两阶段过程,我们称之为 Query Then Fetch
2.在初始查询阶段时,查询会广播到索引中每一个分片拷贝(主分片或者副本分片)。 每个分片在本地执行搜索并构建一个匹配文档的大小为 from + size 的优先队列。PS:在搜索的时候是会查询Filesystem Cache的,但是有部分数据还在Memory Buffer,所以搜索是近实时的。
3.每个分片返回各自优先队列中 所有文档的 ID 和排序值 给协调节点,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
4.接下来就是 取回阶段,协调节点辨别出哪些文档需要被取回并向相关的分片提交多个 GET 请求。每个分片加载并丰富文档,如果有需要的话,接着返回文档给协调节点。一旦所有的文档都被取回了,协调节点返回结果给客户端。
禁用doc_values
doc_values默认是True 在使用如下查询的时候会用到Sorting, aggregations, and access to field values in scripts disable doc_value会怎样 消极影响:sort、aggregate、access the field from script将会无法使用 积极影响:节省磁盘空间
PUT my_index
{
"mappings": {
"my_type": {
"properties": {
"mystring": {
"type": "keyword",
"doc_values": false
}
}
}
}
}