查看手册
man bash
重定向
2>&1 #错误重定向到标准输出
&> file #标准和错误都输出到file
1>&2 #标准输出重定向到错误
花括号{}
touch playground/dir-{00{1..9},0{10..99},100}/file-{A..Z}。#花括号可以嵌套
ls -A
ls -A 显示所有文件除了当前目录和上级目录. ..
切换目录
~username 表示用户的家目录
搜索历史命令
Ctrl-r搜索历史命令
Ctrl-j编辑搜索出来的历史命令
umask
umask (rw-rw-rw)-umask,比如umask=0002则,默认文件权限为rw-rw-r
目录比文件多了x权限默认目录权限rwx-rwx-r-x
root权限执行
su -c 'ls /root' 执行root权限而不切换到root
chown
chown bob: 文件所有者改为用户 bob,文件用户组改为,用户 bob 登 录系统时,所属的用户组。
:admins 把文件用户组改为组 admins,文件所有者不变。
vmstat
vmstat 2 5
表示隔2秒时间进行5次采样。
vmstat -d 查看磁盘的读/写
vmstat -S M 显示单位M
vim编辑器
w移动到下一个单词或标点符号的开头。
W 移动到下一个单词的开头,忽略标点符号。
b移动到上一个单词或标点符号的开头。
0移动到当前行的行首。
$移动到当前行的末尾。
^移动到当前行的第一个非空字符。
a光标在当前word后面插入
A光标在当前行的末尾插入
x 删除当前光标的字符
3x 当前字符及其后的两个字符。
d$ 从光标位置开始到当前行的行尾。
d0 从光标位置开始到当前行的行首。
dˆ 从光标位置开始到文本行的第一个非空字符。
dG 从当前行到文件的末尾。
dW 从光标位置开始到下一个单词的开头。
yy 当前行。
5yy 当前行及随后的四行文本。
yW 从当前光标位置到下一个单词的开头。
y$ 从当前光标位置到当前行的末尾。
y0 从当前光标位置到行首。
yˆ 从当前光标位置到文本行的第一个非空字符。
yG 从当前行到文件末尾。
y20G 从当前行到文件的第20 行。
p 命令把所复制的文本粘贴到当前行之下
P 命令把所复制的文本粘贴到当前行之上
J(不要与小写的j 混淆了,j 是用来移动光标的)把行与行之间连接起来。(非常实用)
:%s/Line/line/g
条目含义
: 冒号字符运行一个ex 命令。
% 指定要操作的行数。% 是一个快捷方式,表示从第一行到
最后一行。另外,操作范围也可以用1,5 来代替(因为我们
的文件只有5 行文本),或者用1,$ 来代替,意思是“从第
一行到文件的最后一行。”如果省略了文本行的范围,那么
操作只对当前行生效。
s 指定操作。在这种情况下是,替换(查找与替代)。
/Line/line 查找类型与替代文本。
g 这是“全局”的意思,意味着对文本行中所有匹配的字符串
执行查找和替换操作。如果省略g,则只替换每个文本行中
第一个匹配的字符串。
vi编辑多个文件
vim file1 file2 ...
n/N切换文件
n!/N!放弃更改并切换文件
:r foo.txt 将foo.txt的文件内容插入到当行的下一行
:w foo1.txt 保存副本
ZZ保存并退出
vim编写脚本常用设置
:syntax on #打开语法高亮
:set hlsearch #打开这个选项是为了高亮查找结果
:set tabstop=4 #设置一个tab 字符所占据的列数。默认是8 列。
:set autoindent #新的文本行缩进与刚输入的文本行相
同的列数
元数据
stat example.txt查看文件的元数据
ls -i example.txt
df -i 查看分区的inode信息
find
find
find命令搜索出来是无序的
find ~ \( -type f -not -perms 0600 \) -or \( -type d -not -perms 0700 \)
find playground \( -type f -not -perm 0600 -exec chmod 0600 '{}' ';' \)
-or \( -type d -not -perm 0711 -exec chmod 0700 '{}' ';' \)
find ~ -type f -name '*.BAK' -delete
find ~ -type f -name 'foo*' (-ok|-exec) ls -l '{}' ';' #{} 是当前路径名的符号表示,分号是要求的界
定符表明命令结束。
find . -type f -size +100M -print0 | xargs -0 du -h
find . -iname ‘*.jpg’ -print0 | xargs –null ls -l
find . -type f -exec ls -l {} \;
find ~ -type f -name 'foo*' -exec ls -l '{}' ';' #找到一个文件就执行一次ls -l
find ~ -type f -name 'foo*' -exec ls -l '{}' + #全部参数都找到了再一次性执行一次ls -l
find ~ -type f -name 'foo\*' -print | xargs ls -l
find ./ -type f -name "*.sh"|xargs -i mv {} /opt/ # 加-i 参数直接用 {}就能代替管道之前的标准输出的内容;
find . -type f -name "*.log" | xargs -I {} cp {} /tmp/n/ #加 -I 参数 需要事先指定替换字符。
#xargs 会为ls 命令构建参数
列表,然后执行ls 命令,也是只执行一次ls,如果参数过长
xargs
cat exsample.txt |xargs #多行转化成1行输出
cat exsample.txt |xargs -n 2 #每行显示2个参数-L 和-n区别在文件名不会因为空格而被分开
echo helloXwelcomeXworld |xargs -d X #-d设置定界符X
cat args.txt |xargs -n 1 ./cecho.sh #将格式化参数传递给脚本,可代替for循环
cat args.txt |xargs -I {} ./cecho.sh -p {} -1 #-I替换
-i默认{},-I 可以指定其他替换字符
-P 指定并发数
rsync
rsync -av --delete /etc /home /usr/local /media/BigDisk/backup #--delete删除可能在目的设备中已经存在但却不再存在于源设备中的文件
grep
grep -l bzip dirlist*.txt #打印包含匹配项的文件名,而不是文本行本身
-L#相似于-l 选项,但是只是打印不包含匹配项的文件名
-n#在每个匹配行之前打印出其位于文件中的相应行号
-c#打印匹配的数量
-v#打印不匹配的行
-h#查询多文件时不显示文件名。
正则表达
BRE 可以辨别以下元字符:^ $ . [ ] *
ERE 添加了以下元字符: ( ) { } ? + |
BRE 中,字符“(”,“)”,“{”,和“}”用反斜杠转义后,
被看作是元字符, 相反在ERE 中,在任意元字符之前加上反斜杠会导致其被看作是一个文本字
符。
sort
sort -t ':' -k 7 /etc/passwd | head #-t 选项来定义分隔符
sort -k 3.7nbr -k 3.1nbr -k 3.4nbr distros.txt -o newfile.txt
#-o输出到文件,-k 3.7第三个地段的第7个字符开始排序-b忽略每行开头的空格,从第一个非空白字符开始排序-n根据数字值执行排序,而不是字母值。-r降序。-u消除重复行
uniq
-d 只输出重复行
-i 在比较文本行的时候忽略大小写。
cut
cut -d ':' -f 1 /etc/passwd
tr
echo "lowercase letters" | tr [:lower:] A #所有小写转化为A
echo "lowercase letters" | tr a-z A-Z #小写转大写
sed
echo "aaabbbccc" | sed 's/b/B/g' #全部替换b为B
awk传递外部变量
awk '{print v1 v2}' v1=$var1 v2=$var2
awk '{count[$0]++}END{for(i in count){printf("word%-14s %d\n",i,count[i])}}' #使用for循环
awk 'NR==3,NR==5' exsample.txt #打印3-5行直接的文本
awk '/star_pattern/,/end_pattern/' exsample.txt #对应pattern直接的文本
函数
[ function ] funname [()]
{
action;
[return int;]
}
function funct #函数名必须和{之间有空格
{
echo "Step 2"
return
}
func2() {
echo "func2"
return
}
#在脚本中shell 函数定义必须出现在函数调
用之前。
funct
func1
func2
unset -f func #删除函数
说明:
(1)可以带function fun() 定义,也可以直接fun() 定义,不带任何参数。
(2)参数返回,可以显示加:return 返回,如果不加,将以最后一条命令运行结果,作为返回值。 return后跟数值n(0-255),还可以通过echo 直接返回。
注意
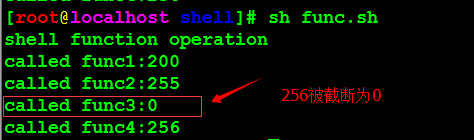
shell中通过return返回是有限制的,最大返回255,超过255,则从0开始计算。
#!/bin/sh
echo "shell function operation"
func1()
{
local num1=100
local num2=100
let sum=$num1+$num2
return $sum
}
func2()
{
local num1=100
local num2=155
let sum=$num1+$num2
return $sum
}
func3()
{
local num1=100
local num2=156
let sum=$num1+$num2
return $sum
}
func4()
{
local num1=100
local num2=156
let sum=$num1+$num2
echo $sum
}
func1
echo "called func1:$?"
func2
echo "called func2:$?"
func3
echo "called func3:$?"
sum=`func4`
echo "called func4:$sum"
执行结果如下所示:
cat
cat <<\_EOF_ #<<\反斜杠的作用是禁止拓展,也就是输入啥就是啥
cat -s压缩空行
cat -n f1.txt,查看f1.txt文件的内容,并且由1开始对所有输出行进行编号。
cat -b f1.txt,查看f1.txt文件的内容,用法与-n相似,只不过对于空白行不编号。
cat -s f1.txt,当遇到有连续两行或两行以上的空白行,就代换为一行的空白行。
局部变量
foo=0
funct_1 () {
local foo #定义局部变量,不影响外部变量foo
foo=1
echo "funct_1: foo = $foo"
}
funct_1
echo $foo
#结果如下
#funct_1: foo = 1
#0
if
[[ string1 =~ regex ]]#regex不能加引号,否则不匹配
if [[ "$INT" =~ ^[0-9]+$ ]] #匹配整数
if [[ $INT =~ ^-?[[:digit:]]+$ ]]
[[ ]] 添加的另一个功能是== 操作符支持类型匹配,正如路径名展开所做的那样。如:
if [[ $FILE == foo.* ]] #正则表达式也不能加引号,否则不匹配
&&,||,-a,-o,!用法
if [[ $1 -gt 1 && $1 -gt 5 ]]
if [ $1 -gt 1 -a $1 -gt 5 ]
if [ $1 -gt 1 ] && [ $1 -gt 5 ]
追踪脚本
方法1:
sh -x script.sh
方法2: 在脚本中set 命令加上-x 选项,为脚本中的一块选择区域,而不是整个脚本启用追 踪。set 命令加上-x 选项来启动追踪,+x 选项关闭追踪,如
#!/bin/bash
# trouble: script to demonstrate common errors
number=1
set -x # Turn on tracing
if [ $number = 1 ]; then
echo "Number is equal to 1."
else
echo "Number is not equal to 1."
fi
set +x # Turn off tracing
or || and &&
mkdir temp && cd temp #只有如果command1执行成功后,才会执行command2。
[ -d temp ] || mkdir temp #只有如果command1 执行失败后,才会执行command2
case
#!/bin/sh
echo "Test Of CASE"
case $1 in
1)
echo "1"
;;
a|A)
echo "a|A"
;;& #添加的“;;&”的语法允许case 语句继续执行下一条测试,而不是简单地终止运行。
[[:alpha:]])
echo "alpha"
;;&
???)
echo "three character"
;;
[ABC][0-9])
echo "[ABC][0-9]"
;;
*.txt)
echo "*.txt"
;;
*)
参数
$0 文件名 $n 第N个参数 $# 参数个数 $* 和$@的区别在于加双引号之后被看做是单个字符串 $@ $!Shell最后运行的后台Process的PID $$脚本运行的当前进程ID号 $?最后运行的命令的结束代码(返回值)即执行上一个指令的返回值
大小写转换
方法1:
#!/bin/bash
# ul-declare: demonstrate case conversion via declare
declare -u upper
declare -l lower
if [[ $1 ]]; then
upper="$1"
lower="$1"
echo $upper
echo $lower
fi
方法2:
#bash3.x
$ echo $VAR_NAME | tr '[:upper:]' '[:lower:]'
$ echo $VAR_NAME | tr '[:lower:]' '[:upper:]'
#bash4.x
${parameter„} 把 parameter 的值全部展开成小写字母。
${parameter,} 仅仅把 parameter 的第一个字符展开成小写字母。
${parameterˆˆ} 把 parameter 的值全部转换成大写字母。
${parameterˆ} 仅仅把 parameter 的第一个字符转换成大写字母(首字母 大写))
加一减一
let c++/c--
$((++foo)) #先加再返回
$((foo++)) #先返回再加
[me@linuxbox~]$ foo=1
[me@linuxbox~]$ echo $((++foo))
2
[me@linuxbox~]$ echo $foo
2
[me@linuxbox~]$ foo=1
[me@linuxbox~]$ echo $((foo++))
2
[me@linuxbox~]$ echo $foo
2
三元运算符号
[me@linuxbox~]$ a=0
[me@linuxbox~]$ ((a<1?++a:--a))
[me@linuxbox~]$ echo $a
1
[me@linuxbox~]$ ((a<1?++a:--a))
[me@linuxbox~]$ echo $a
0
数组
declare -a array1 #下标数字
declare -A colors。#下标可以是其它
colors["red"]="#ff0000"。
colors["green"]="#00ff00"
colors["blue"]="#0000ff"
name[subscript]=value
name=(value1 value2 ...)
days=([0]=Sun [1]=Mon [2]=Tue [3]=Wed [4]=Thu [5]=Fri [6]=Sat)
输出整个数组的内容*和@区别
[me@linuxbox ~]$ animals=("a dog" "a cat" "a fish")
[me@linuxbox ~]$ for i in ${animals[*]}; do echo $i; done
a
dog
a
cat
a
fish
[me@linuxbox ~]$ for i in ${animals[@]}; do echo $i; done
a
dog
a
cat
a
fish
[me@linuxbox ~]$ for i in "${animals[*]}"; do echo $i; done
a dog a cat a fish
[me@linuxbox ~]$ for i in "${animals[@]}"; do echo $i; done
a dog
a cat
a fish
确定数组元素个数
[me@linuxbox ~]$ a[100]=foo
[me@linuxbox ~]$ echo ${#a[@]} # 数组元素个数
1
[me@linuxbox ~]$ echo ${#a[100]} #元素长度
3
数组使用的下标
[me@linuxbox ~]$ foo=([2]=a [4]=b [6]=c)
[me@linuxbox ~]$ for i in "${foo[@]}"; do echo $i; done
a
b
c
[me@linuxbox ~]$ for i in "${!foo[@]}"; do echo $i; done
2
4
6
for
for var;do : ;done
等同于
for var in "$@";do : ;done
数组末尾添加元素
[me@linuxbox~]$ foo=(a b c)
[me@linuxbox~]$ echo ${foo[@]}
a b c
[me@linuxbox~]$ foo+=(d e f)
[me@linuxbox~]$ echo ${foo[@]}
a b c d e f
删除数组
[me@linuxbox ~]$ foo=(a b c d e f)
[me@linuxbox ~]$ echo ${foo[@]}
a b c d e f
[me@linuxbox ~]$ unset foo
[me@linuxbox ~]$
删除单个元素
[me@linuxbox~]$ foo=(a b c d e f)
[me@linuxbox~]$ echo ${foo[@]}
a b c d e f
[me@linuxbox~]$ unset 'foo[2]' #数组元素必须用引号引起来为的是防止shell 执行路径名展开操作
[me@linuxbox~]$ echo ${foo[@]}
a b d e f
任何引用一个不带下标的数组变量,则指的是数组元素0:
[me@linuxbox~]$ foo=(a b c d e f)
[me@linuxbox~]$ echo ${foo[@]}
a b c d e f
[me@linuxbox~]$ foo=A
[me@linuxbox~]$ echo ${foo[@]}
A b c d e f
组命令和子 shell
组命令: { command1; command2; [command3; …] } #花括号与命令之间必须有一个空格,并且最后一 个命令必须用一个分号或者一个换行符终止。 子 shell (command1; command2; [command3;…]) 案例: { ls -l; echo “Listing of foo.txt”; cat foo.txt; } > output.txt #会把三条命令的输出结果分别重定向到output.txt
组命令和子shell区别在于 组命令在当前 shell 中执行它的所有命令,而一个子 shell(顾 名思义)在当前 shell 的一个子副本中执行它的命令。 组命令运行很快并且占用的内存也少。
创建临时文件
tempfile=$(mktemp /tmp/foobar.$$.XXXXXXXXXX) #$$表示当前进程号
mktemp -u new.XXX #不创建任何东西,仅仅显示文件名,至少三个大写的XXX
mktemp -d benderfly.XXXXXX #创建临时目录
wait
等待子进程执行完毕,用在脚本中调用子进程
child-process &
pid=$!
wait $pid #等待最近那个后台进程结束
IFS分隔符
oldIFS=$IFS
录制终端会话
script -t 2> timing.log -a output.session #录制终端会话 scriptreplay timing.log output.session #回放终端会话
readlink读取软连接
readlink 找出符号链接所指向的位置
[root@login4 WRF]# readlink --help
用法:readlink [选项]... 文件...
输出符号链接值或权威文件名。
-f, --canonicalize 递归跟随给出文件名的所有符号链接以标准化,
除最后一个外所有组件必须存在
-e, --canonicalize-existing 递归跟随给出文件名的所有符号链接以标准化,
所有组件都必须存在
-m, --canonicalize-missing canonicalize by following every symlink in
every component of the given name recursively,
without requirements on components existence
-n, --no-newline do not output the trailing delimiter
-q, --quiet,
-s, --silent suppress most error messages
-v, --verbose report error messages
-z, --zero separate output with NUL rather than newline
--help 显示此帮助信息并退出
--version 显示版本信息并退出
bc比较两个数大小
[root@www test]# echo $a
98.7
[root@www test]# echo $b
89.34
[root@www test]# echo "$a > $b"|bc
1
[root@www test]# echo "$b > $a"|bc
0
local局部和全局变量
变量分类
局部变量和环境变量,局部变量只适用于当前shell,而环境变量是全局的,它适用于所有当前shell以及其派生出来的任意子进程
局部变量
局部变量的作用域被限定在创建它们的shell中。
local函数可以用来创建局部变量,但仅限于函数内使用。
局部变量可以通过简单的赋予它一个值或一个变量名来设置。
用declare内置函数来设置,或者省略也可。
格式:
local 变量名=值 #仅限于函数内部使用
变量名=值
declare 变量名=值
局部变量的例子:
[root@www test]# round=world
[root@www test]# echo $round
world
[root@www test]# bash
[root@www test]# echo $round
[root@www test]# exit
exit
[root@www test]# echo $round
world
在上面的岩石中可以看出,当启动一个bash程序,相当于创建一个子shell后,round变在这个子shell中没有被赋值,exit退出子shell后,可以看到父shell中变量round仍有值。
环境变量
环境变量通常又称全局变量,以区别于局部变量,通常,环境变量应该大写,环境变量是已经用export内置命令导出的变量。子shell继承当前父shell的环境变量,并能一直传承下去,但是不可逆向传递。 格式:
export 变量=值
declare -x 变量=值
我们做个示范:
[root@www test]# export NAME="benderfly"
[root@www test]# echo $NAME
benderfly
[root@www test]# bash
[root@www test]#
[root@www test]# echo $NAME
benderfly
[root@www test]# declare -x NAME="Arvin"
[root@www test]# echo $NAME
Arvin
[root@www test]# exit
exit
[root@www test]# echo $NAME
benderfly
上述例子中,父shell中定义的NAME环境变量传递到了子shell中,在子shell中定义的NAME环境变量没有被带到父shell中。
设置变量的三种方法
1) 在/etc/profile文件中添加变量【对所有用户生效(永久的)】 例如:
# vi /etc/profile
export CLASSPATH=./JAVA_HOME/lib;$JAVA_HOME/jre/lib
注:修改文件后要想马上生效还要运行
source /etc/profile 不然只能在下次重进此用户时生效。
2) 在用户目录下的.bash_profile文件中增加变量【对单一用户生效(永久的)】 例如:编辑guok用户目录(/home/guok)下的.bash_profile
$ vi /home/guok/.bash.profile
export CLASSPATH=./JAVA_HOME/lib;$JAVA_HOME/jre/lib
注:修改文件后要想马上生效还要运行
source /home/guok/.bash_profile 不然只能在下次重进此用户时生效。
3) 直接运行export命令定义变量【只对当前shell(BASH)有效(临时的)】 在shell的命令行下直接使用[export变量名=变量值]定义变量, 该变量只在当前的shell(BASH)或其子shell(BASH)下是有效的,shell关闭了,变量也就失效了,再打开新shell时就没有这个变量,需要使用的话还需要重新定义。
bash_profile,.bash_profile和.bashrc的区别
/etc/profile:此文件为系统的每个用户设置环境信息,当用户第一次登录时,该文件被执行. 并从/etc/profile.d目录的配置文件中搜集shell的设置. /etc/bashrc:为每一个运行bash shell的用户执行此文件.当bash shell被打开时,该文件被读取. ~/.bash_profile:每个用户都可使用该文件输入专用于自己使用的shell信息,当用户登录时,该 文件仅仅执行一次!默认情况下,他设置一些环境变量,执行用户的.bashrc文件. ~/.bashrc:该文件包含专用于你的bash shell的bash信息,当登录时以及每次打开新的shell时,该 该文件被读取. ~/.bash_logout:当每次退出系统(退出bash shell)时,执行该文件.
另外,/etc/profile中设定的变量(全局)的可以作用于任何用户,而~/.bashrc等中设定的变量(局部)只能继承/etc/profile中的变量,他们是”父子”关系.
~/.bash_profile 是交互式、login 方式进入 bash 运行的 ~/.bashrc 是交互式 non-login 方式进入 bash 运行的 通常二者设置大致相同,所以通常前者会调用后者。
设置生效:可以重启生效,也可以使用命令:source alias php=/var/eyouim/pub/php/bin/php source /etc/profile
”:”的作用
·啥也不做,只起到占位符的作用
脚本注释、占位符
#!/bin/sh
: this is single line comment
: 'this is a multiline comment,
second line
end of comments'
if [ "1" == "1" ]; then
echo "yes"
else
:
fi
参数拓展
${parameter:-word} 如果parameter没有设置或者为空,替换为word;否则替换为parameter的值
${parameter:+word} 如果parameter没有设置或者为空,不进行任何替换;否则替换为word。
${parameter:=word} 如果parameter没有设置或者为空,把word赋值给parameter。实际parameterd的值真的被替换了,这就是=号的意思。不能用这种方式指派位置参数或特殊参数的值。
${parameter:?word} 如果parameter没有设置或者为空,把word输出到stderr,否则替换为parameter的值。
-、+、? 实际parameter的值并不被修改,扩展只是临时显示成word的值。准确的讲,扩展实际替换的是参数的显示,而不是参数的定义。只有=,才是替换参数的定义。
${parameter:offset} 扩展为parameter中从offset开始的子字符串。
${parameter:offset:length} 扩展为parameter中从offset开始的长度不超过length的字符。
清空文件
: >file
清空文件file的内容。
参数拓展
[root@node56 ~]# : abc=1234
[root@node56 ~]# echo $abc
[root@node56 ~]# : ${abc:=1234}
[root@node56 ~]# echo $abc
1234
[root@node56 ~]# ${abc:=1234}
-bash: 1234: command not found
格式:: ${VAR:=DEFAULT}
当变量VAR没有声明或者为NULL时,将VAR设置为默认值DEFAULT。如果不在前面加上:命令,那么就会把${VAR:=DEFAULT}本身当做一个命令来执行,报错是肯定的。 可以看出来,如果${abc:=1234}前面不加”:”的话,会直接把他当作命令执行